
Resumo do texto:
O objetivo de fazer esse texto é esclarecer um pouco os diversos componentes do ecossistema Hadoop, seja para big data ou data engineering.
Ao final dele espero que você tenha uma visão mais clara desse mundo relativamente novo.
Tabela de Conteúdo
1 – Introdução
Para entendermos o termo big data, precisamos saber alguns números.
Segundo matéria de maio de 2020, do site e-commerce Brasil o mundo possui cerca de 4.57 bilhões de usuários de internet, ja no Brasil, segundo matéria da Agencia Brasil datada da mesma época, cerca de 134 milhões acessaram a rede mundial nos ultimos meses.
Em termos numéricos isso representa um volume enorme de dados. Segundo o site da Domo que faz o infográfico Data Never Sleeps, que estuda o que acontece na internet por minuto, os números são impressionantes, de acordo com o infográfico abaixo.
Segundo o site, a cada minuto são postados 347 mil novos stories no Instagram, 147 mil fotos publicadas no Facebook, 41 milhões de mensagens trocadas pelo WhatsApp, mais de 4.4 milhões de buscas feitas no Google e muito mais.

Ficou impressionado? Eu também fiquei e tem mais…
Segundo as estimativas ao final do ano de 2020 nós teremos produzido 44 zetabytes de dados. Isso mesmo, você leu certo, 44 zeta, isso é dado que não acaba mais.
Mas por que estou falando tudo isso?
Porque esses dados são gerados em diversos formatos, por exemplo, o Youtube tem formato de vídeo e áudio, Instagram, texto, vídeo, imagem e audio, Twitter idem e assim por diante.
Porque o crescimento nesse ritmo veloz dos dados nessa diversidade de formatos, torna inviável o armazenamento nos sistemas tradicionais que usamos a mais de 30 anos.
Para dar conta de lidar com tudo isso precisamos de uma arquitetura complexa e com vários componentes (framework) para dar conta do que chamamos de Big Data.
2 – Desafios das arquiteturas tradicionais
Quando falo de arquiteturas de armazenamento tradicionais, me refiro aos mais utilizados pelas empresas e órgãos públicos, que são os relacionais. Eles armazenam os Data Warehouses, Data Marts e sistemas transacionais, porém quando olhamos para os dados que estão sendo gerados pelas novas plataformas percebemos que fica inviável utilizá-los pelas seguintes, mas não só essas, razões:
a) a maioria dos dados gerados pelas plataformas modernas são semi-estruturados ou não-estruturados, mas os sistemas relacionais foram desenhados para armazenar dados estruturados, basicamente em linhas e colunas.
b) os bancos de dados relacionais geralmente escalam mais verticalmente, isso significa que tem de adicionar mais memória, disco, processamento e etc. ao mesmo sistem e isso pode ficar caro.
c) apesar do Data Warehouse existir a muito tempo, os dados continuam em silos e a integração deles é onerosa, tanto em tempo, quanto em dinheiro.
Então, como lidar com o big data? É aqui que o Hadoop começa a aparecer.
3 – O que é Hadoop?
Segundo a Wikipedia o Hadoop é uma plataforma de software em Java de computação distribuída voltada para clusters e processamento de grandes volumes de dados com atenção a tolerancia a falhas.
Teve origem num projeto do Google chamado GFS – Google File System, que também inspirou outro projeto intitulado de MapReduce.
O Google sentiu o peso do desafio quando começaram rankear as páginas web. Eles acharam os bancos de dados relacionais muito caros e pouco flexíveis para o que estavam querendo fazer, então eles criaram o GFS.
Como dito acima, ele é focado em ambiente distribuído e o ponto alto é que roda em hardware barato e oferece paralelização, escalabilidade e confiabilidade. Isso foi determinante para que o projeto decolasse.
O Yahoo, passou a utilizar massivamente o Hadoop e também virou um dos maiores contribuidores de código do produto que hoje está sob a tutela da Apache Foundation.
Se você também está curioso como eu, para saber porque se chama Hadoop, clica aqui e assista ao vídeo.
Resumindo, o Hadoop é um framework de código aberto embasado no GFS que pode trabalhar com grandes volumes de dados num ambiente distribuído. Esse ambiente é formado por um cluster com várias máquinas que trabalham juntas, dando a impressão de ser uma só.
O que você deveria saber sobre o Hadoop:
a) ele é altamente escalável porque lida com os dados de maneira distribuída;
b) comparado a escalabilidade vertical dos RDBMS normais, o Hadoop oferece escalabilidade horizontal;
c) ele cria e salva réplica dos dados tornando-o tolerante a falhas;
d) ele é econômico, pois todos os nós dos clusters podem ser levantados com máquinas simples e baratas;
e) o Hadoop utiliza o conceito de data locality, ou seja, processa os dados nos nós do próprio cluster, sem necessidade de movimentá-los para outro local, reduzindo assim o tráfego de dados pela rede;
f) ele pode manipular qualquer tipo de dado, seja estruturado, semi estruturado e não estruturado. Nos dias atuais temos uma diversidade de dados enorme, sem formato específico, vindo de Twitter, Instagram, sensores de IoT e etc, e ter a flexibilidade de receber e manipular essa imensidão de dados é extremamente importante;
Vamos agora falar um pouco mais sobre os componentes do ecossistema Hadoop, pois eu ficava bastante confuso com a infinidade de produtos que ele tem e o que cada um faz. Espero que ajude vocês a entenderem melhor.
4 – Os 11 componentes do ecossistema Hadoop
Vamos começar dando uma visão geral dos produtos que compõem o ecossistema, conforme figura abaixo.
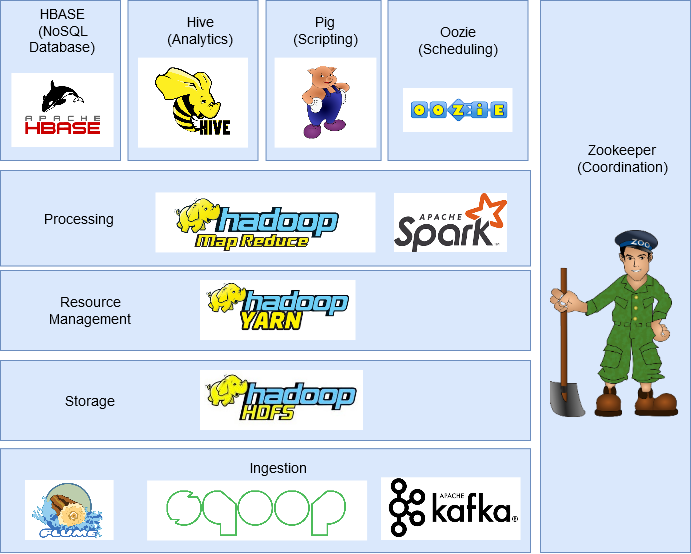
Agora vamos falar um pouco mais sobre cada um dos componentes do ecossistema Hadoop.

HDFS – Hadoop Distribuited File System
Esse é o componente que armazena dados em formato de arquivos no Hadoop.
Cada arquivo é divido em blocos de 128 mb (configuráveis) e são gravados em diferentes máquinas do cluster.
A sua arquitetura possui dois componentes principais que são o name node e o data node.
Name node: é o nó mestre e há apenas um por cluster. Sua tarefa principal é gerenciar os arquivos e os blocos armazenados em cada cluster. Ele basicamente mapeia a localização, faz a divisão dos arquivos em blocos e controla a localização de suas réplicas.
Data Node: é o nó escravo e podem ter vários por cluster. Sua missão é recuperar os dados quando requisitado, de onde eles estiverem. São eles que fazem o armazenamento efetivo dos dados e podem conter inúmeros blocos de diferentes arquivos.
Eles estão sempre reportando ao name node quais blocos estão guardando e todas alterações que foram efetuadas neles.
Map Reduce

Para manejar grandes volumes de dados e extrair o máximo do big data o Hadoop conta com um algoritmo, também introduzido pelo Google, chamado Map Reduce que facilita a distribuição e execução de uma tarefa paralelamente no cluster. Sua missão é basicamente dividir uma tarefa em várias e processa em máquinas diferentes.
Utilizando-me do ditado popular, ele divide para conquistar e executa os processos nas maquinas do cluster evitando assim o tráfego intenso de rede.
Ele possui duas importantes etapas: Map e Reduce, em tradução livre, mapear e reduzir que nós veremos representada na figura abaixo.
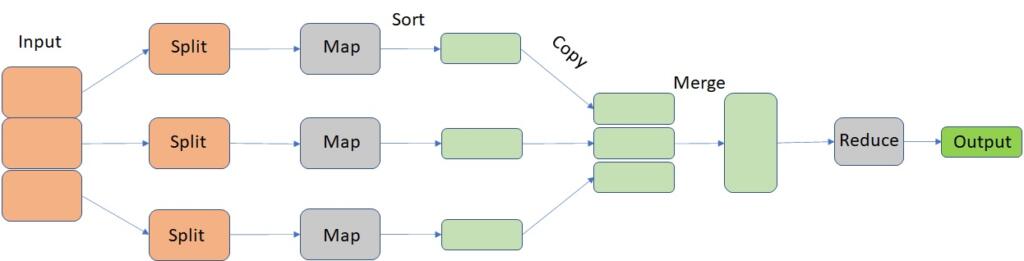
A parte de input é dividida (split) em várias tarefas. A fase de mapeamento filtra, agrupa, classifica e ordena os dados.
Cada mapa trabalha em paralelo, divididos em máquinas diferentes processando um conjunto de dados. Como saída, as funções Map produzem normalmente pares chaves/valor.
A saída é conhecida como a fase de Reduce, onde ele agrega os dados, sumariza os resultados e armazena no HDFS.
Em resumo o Reduce fornece o resultado final da execução, juntando os resultados de processos executados pelo Map.
Hadoop YARN

O YARN ou Yet Another Resource Negotiator gerencia os recursos no cluster e as aplicações no Hadoop. Ele permite que os dados armazenados no HDFS possam ser processados em vários engines como processamento em lote, streaming e etc.
Segundo a Wikipedia, ele se divide basicamente em duas funcionalidades de gerenciamento de recursos e agendamento/monitoramento de jobs em daemons separados.
Em resumo, ele coordena como as aplicações são executadas.
HBASE

O HBase é um banco de dados NoSQL, open-source com estrutura colunar.
Roda com o HDFS e pode trabalhar com diversos formatos de dados, permitindo o processamento em tempo real e randômico de leitura/gravação nos dados.
A função principal dele é hospedar grandes tabelas – bilhões de linhas x milhões de colunas – sobre clusters de hardware comum, muito semelhante ao HDFS.
Apache Pig

Esse componente do ecossistema Hadoop originou-se de um projeto desenvolvido pelo Yahoo! por volta de 2006 porque sentiram a necessidade de ter um ferramenta para executarem jobs MapReduce de maneira ad-hoc, ou mais simplificada para os usuários.
O Pig foi desenvolvido para analisar grandes conjuntos de dados e simplifica a escrita de funções map reduce ou Spark. Eles está estruturado em dois componentes: Pig Latin e Pig engine.
Pig Latin é a linguagem de script semelhante ao SQL e o Pig Engine é o motor de execução do que é desenvolvido pelo Pig Latin. Internamente o script desenvolvido no Pig Latin é convertido em funções MapReduce, tornando a vida dos programadores que não conhecem Java muito mais fácil.
Hive

O Hive é um systema de data warehouse distribuído desenvolvido pelo facebook.
Ele permite de maneira simples, ler, gravar e gerenciar grandes arquivos no HDFS. Tem sua própria linguagem de consulta chamda HQL – Hive Querie Language – que é muito similar à linguagem SQL.
Ela simplifica a escrita de funções MapReduce usando a linguagem HQL.
Sqoop

Sabemos que muitos dados estão armazenados em bancos de dados relacionais. Como eles já estão a muito tempo no mercado são uma fonte importante de dados.
É aqui que Sqoop desempenha um papel importante para trazer esses dados dos bancos estruturados para dentro do HDFS.
Todos comandos escritos internamente no Sqoop são convertidos em tarefas MapReduce que são carregadas no HDFS, tem compatibilidade com a maioria dos bancos relacionais (Oracle, SQL Server, MySQL, PostGree e etc.) e pode exportar dados do HDFS para esses bancos.
Flume
O Flume é software de código aberto, confiável e distribuído utilizado para coletar, agregar e mover grandes quantidades de dados para o HDFS. Segundo a Wikipedia, possui uma arquitetura simples e flexível baseada em fluxo de dados de streaming. Ela é bastante robusta e tolerante a falhas pois possui vários mecanismos de failover e recuperação caso seja necessário.
Ele pode coletar os dados em real time ou batch.
Kafka

Existem inúmeras aplicações gerando dados e muitas outras consumindo-os, porém conectá-las individualmente é uma tarefa bastante difícil. Quando essa necessidade aparece é que entra o Kafka.
Ele fica entre as aplicações que geram dados (producers/produtores) e as que consomem os dados (consumers/consumidores).
A plataforma, segundo a Wikipedia, tem por objetivo entregar uma plataforma integrada e de baixa latência para tratamento de dados em tempo real.
O Kafka tem processamento distribuído, replicação e tolerância a falhas nativo. Ele pode lidar com streaming de dados e permite a análise de dados em tempo real.
Ele foi originalmente desenvolvido pelo Linkedin e teve seu código aberto no início de 2011.
Oozie

O Oozie é um agendador de workflows que permite os usuários fazerem o agendamento dos jobs desenvolvidos em várias plataformas, como MapReduce, Pig, Hive e etc.
Usando o Oozie é possível criar um job que possa chamar de maneira orquestrada, outros jobs ou pipelines de dados, seja de maneira sequencial ou paralela para executar uma determinada tarefa.
É um produto open-source, confiável e escalável que auxilia muito as tarefas de quem usa o ecossistema Hadoop.
Zookeeper

Como já vimos manter um ambiente Hadoop é bastante desafiador. Sincronizar, coordenar e manter as configurações de um ambiente de cluster Hadoop exige bastante esforço, para resolver esse problema entra em cena o Zookeeper.
Ele é um software open-source, distribuído, e com um serviço centralizado para manter as informações de configuração, naming , sincronização distribuída e um grupo de serviços para todo o cluster.
Spark

O Spark é um framework de código aberto, alternativo ao Hadoop, desenvolvido em Scala que também oferece suporte a diversas aplicações escritas em Java, Python e etc.
Comparado com o MapReduce, ele executa o processamento em memória aumentando consideravelmente a velocidade de execução desses processos.
Outro ponto importante a ser considerado é que além dele executar processos em batch igual o Hadoop, ele também consegue trabalhar em tempo real.
Além disso o Spark tem seu próprio ecossistema:
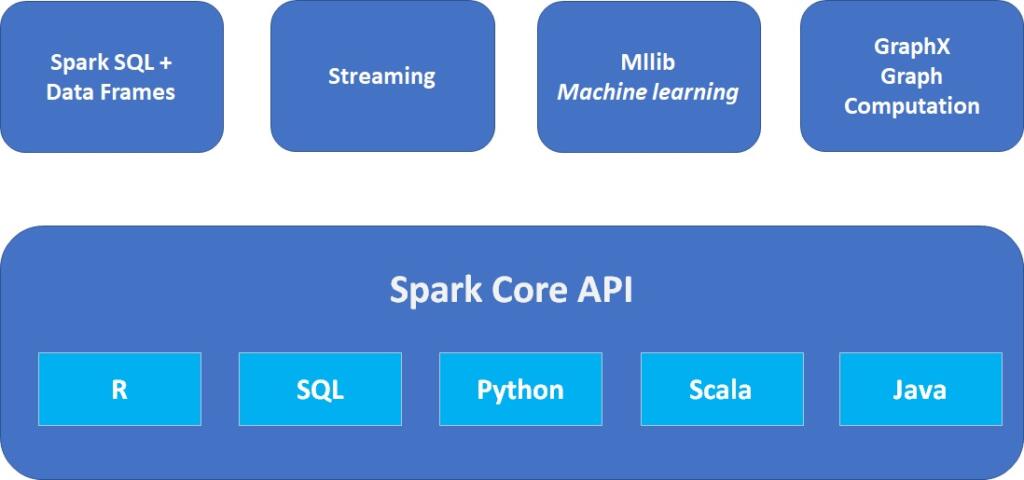
Spark Core: é o core da aplicação, o principal mecanismo de execução do Spark e outras API´s construídas sobre ele.
Spark SQL API: permite fazer queries/consultas em dados estruturados em data frames ou tabelas Hive.
Streaming API: permite o Spark lidar com dados em tempo real. Ele se integra facilmente com uma variedade de fontes de dados como Kafka, Flume, Twitter e etc.
MLlib: é uma biblioteca de machine learning escalável que permite executar algorítimos de ciência de dados aproveitando as funcionalidades do Spark ao mesmo tempo, sem perda drástica de performance.
GraphX: é um engine de computação gráfica que permite os usuários interagir, construir e transformar dados em gráficos e vem com uma biblioteca de algorítimos comuns.
Etapas de um processo de Big Data
Com tantos componentes do ecossistema Hadoop fica um pouco difícil no começo para entender onde cada peça se encaixa e o que faz. Por isso, achei interessante fazer um gráfico e mostrar como eles trabalha em cada etapa do processo de big data.
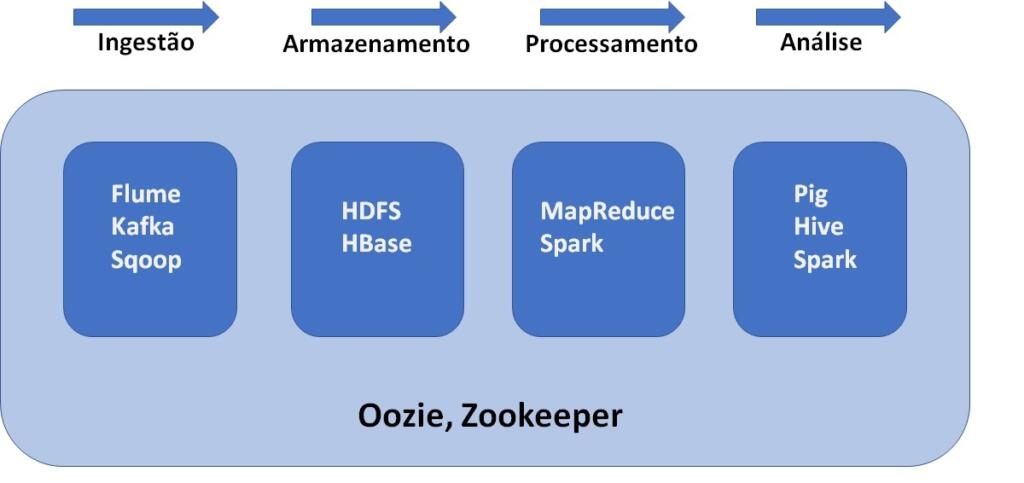
– Flume, Kafka, Sqoop são utilizados para fazer a ingestão de dados no HDFS.
– O HDFS é a unidade de armazenamento do Hadoop. Até os dados importados do HBase também são armazenados no HDFS.
– MapReduce e Spark são usados para processar os dados no HDFS e executar várias outras tarefas.
– Pig, Hive e Spark são utilizados para analisar dados.
– Oozie ajuda a agendar as tarefas e por funcionar com várias plataformas é utilizado ao longo das etapas.
– Zookeeper sincroniza todos os nós do cluster e é utilizado em todas as etapas.
Considerações finais
Bem, se você chegou até aqui é porque o texto foi de alguma maneira útil e espero que esse artigo tenha te ajudado a entender um pouco mais sobre Big Data, porque os sistemas tradicionais tem dificuldades de lidar com isso e os componentes importantes do ecossistema Hadoop.
Quando decidi escrever sobre, tinha muita dificuldade de entender o que cada componente fazia e confesso que preparar esse artigo me ajudou muito a compreender como as coisas funcionam.
Não foi fácil, deu trabalho, mas valeu a pena.
Se gostaram, compartilhem, divulguem e comentem, isso me motiva a continuar escrevendo.
Até a próxima!



